Exciting news! TCMS official website is live! Offering full-stack software services including enterprise-level custom R&D, App and mini-program development, multi-system integration, AI, blockchain, and embedded development, empowering digital-intelligent transformation across industries. Visit dev.tekin.cn to discuss cooperation!
This article provides an in-depth analysis of the core underlying logic of large AI models, covering the entire workflow from Tokenization and Embedding semantic vectors to Retrieval-Augmented Generation (RAG). It demystifies how large models "understand language" with plain language, helping AI beginners and enterprise developers master key technologies such as Tokens, vectors, retrieval and generation, and lay a solid foundation for AI application development.
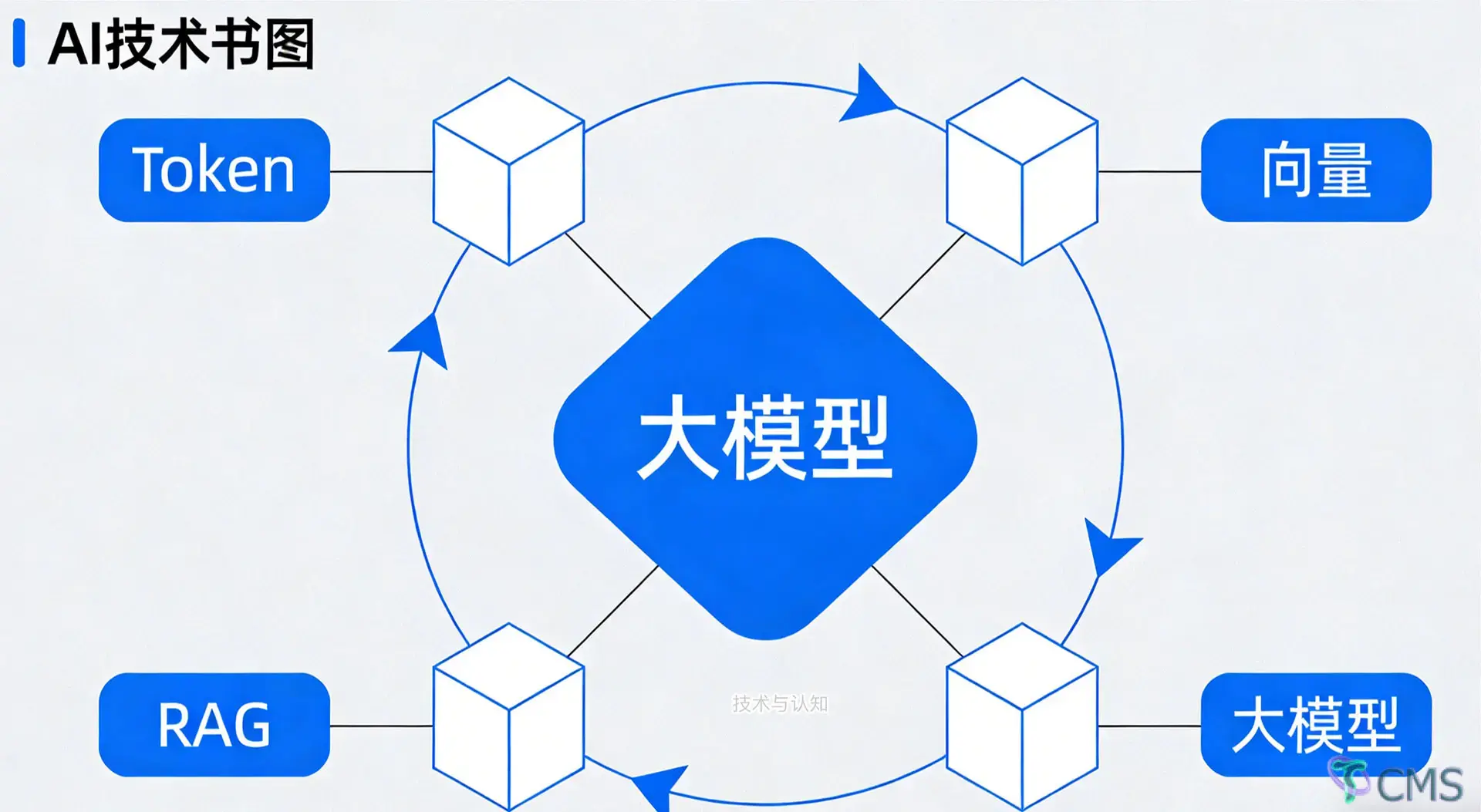
This article avoids fancy frameworks and complex formulas, and only starts from the most fundamental logic: it thoroughly explains the entire process of large models "hearing—thinking—responding" from Tokenization and Embedding vectors to semantic representation and RAG. It is suitable for AI beginners, backend developers switching to AI, and those who want to truly understand the principles rather than just using the tools.
Human text is just a string of meaningless symbols to models. The first step for large models to process language is to convert natural language into the smallest model-recognizable units—Tokens.
A Token is neither a character nor a word, but a minimal processing unit defined by the model:
For English: Usually split into roots, prefixes and whole words
For Chinese: Usually split into single characters and common words
Example: The sentence What is the main function of RAG? is split into: RAG / 的 / 主要 / 作用 / 是 / 什么.
Each segment is mapped to a unique numeric ID, like an "ID card" for language. Models do not process text directly, only these numeric sequences.
Storing all words in a vocabulary would lead to:
A bloated vocabulary (hundreds of thousands or even millions of entries)
Massive video memory usage and low computing efficiency
This is why modern models uniformly adopt the Byte Pair Encoding (BPE) subword tokenization algorithm:
Retain high-frequency words in full
Split low-frequency words into smaller units
Further split rare and new words until matching entries in the vocabulary
Core Objective: Cover almost all language scenarios with a limited vocabulary (usually 30,000 to 300,000 entries), while ensuring no loss of semantics and affordable computing costs.
In a nutshell: Tokens = the gateway to language digitization; BPE = the optimal solution for controlling vocabulary size.
Tokens only convert text into numeric IDs with no inherent semantics. The key step that enables AI to understand "meaning" is Embedding (word/sentence vectors).
The essence of Embeddings: Mapping a piece of text to a point (vector) in a high-dimensional space.
Text with similar semantics is closer in this space, while irrelevant text is farther apart. This forms the underlying mathematical foundation for all semantic search, recommendation systems and RAG technology.
A common misconception among beginners: Thinking Embeddings are pre-written "dictionaries of meaning"—this is entirely incorrect.
When a model is initialized, it creates a huge matrix of vocabulary size × vector dimension, filled with random decimals ranging from -1 to +1. Each Token ID corresponds to a row in this matrix, which is the initial vector—at this stage, the vector has no semantic meaning and is just a string of random numbers.
Vector dimension can be understood as the number of features used to describe semantics. A 768-dimensional vector, for example, describes a word or sentence with 768 "hidden features" (e.g., part of speech, sentiment, theme), all of which are automatically learned by the model without manual annotation.
The reason why dimensions are mostly powers of two is not a mathematical mystery, but a result of hardware engineering adaptation:
GPUs/NPUs are based on parallel computing at the underlying level
Memory reading requires address alignment
Power-of-two dimensions (128, 256, 1024) maximize bandwidth utilization and reduce memory fragmentation
Although 768 is not a pure power of two, 768 = 3 × 256, and 256 is the standard block size of mainstream chips—making it highly efficient for computation and a standard choice for models such as BERT and LLaMA.
Initial vectors are random; semantics are "forged" through prediction tasks.
Typical process (taking autoregressive models as an example):
Input text → Retrieve Token vectors from the matrix
The model performs the task: Predict the next word
Compare the predicted result with the ground truth and calculate the Loss
Backpropagate and adjust all vectors by a tiny margin
Repeat for hundreds of millions of iterations
A stable pattern eventually forms:
Words in similar contexts (e.g., apple, banana, orange) → their vectors move closer
Irrelevant words (e.g., apple, keyboard, universe) → their vectors move farther apart
The core truth in one sentence: Embeddings are not designed, but forged. Vector distance = semantic similarity.
Large models have two inherent flaws:
Knowledge cutoff: No updates after training
Hallucinations: Confidently generating false content for unseen information
Retrieval-Augmented Generation (RAG) is an engineering architecture (not a new model) created to solve these two problems.
Standard RAG consists of two major phases:
Document Chunking: Split long documents into small segments to ensure semantic integrity, compliance with Embedding model length limits, and compatibility with the large model's context window.
Embedding: Convert each segment into a vector.
Storage in Vector Database: Establish an index (e.g., HNSW) for fast Approximate Nearest Neighbor (ANN) search.
Convert the user's question into a vector
Vector Retrieval: Find the most similar segments in the database
Prompt Chunking: Combine the question and reference segments and feed them to the large model
Answer Generation: The model generates responses based only on the provided materials
The essence of RAG: Transforming large models from a "closed-book exam" to an open-book exam.
Many beginners ask: Why not embed entire documents directly? This is not feasible for purely engineering reasons:
Embedding models have a maximum input length; overlong text will be truncated or cause errors
Excessively long text leads to "semantic averaging" and a sharp drop in retrieval accuracy
Limited context window prevents large models from processing entire books
Imprecise retrieval recall fails to locate the exact sentences containing answers
Document chunking is a critical engineering step for effective RAG.
Brute-force vector retrieval (calculating distances for the entire database) freezes the system with large datasets. The industry uniformly uses Approximate Nearest Neighbor (ANN) algorithms.
Core Idea: Sacrifice a tiny amount of accuracy for an order-of-magnitude speed boost.
Through index structures such as trees and graphs (e.g., HNSW):
No full database comparison required
Only fine-screening in candidate sets
Accuracy usually maintained at over 95%
Speed increased by tens or even hundreds of times
This is the underlying support for RAG's real-time online response.
This is the most commonly confused point in interviews and architecture design.
| Comparison Dimension | Large Models | RAG |
|---|---|---|
| Essence | Generative models responsible for language understanding and generation | A retrieval+generation engineering architecture, not a model |
| Role | The "brain" | External reference book + retriever |
| Knowledge Source | Fixed training data, no real-time updates | External knowledge base, support real-time addition/deletion/modification |
| Major Flaw | Hallucinations, outdated knowledge, inability to access private data | Solves hallucinations and ensures responses are based on real information |
| Core Capability | Probabilistic word prediction for fluent and natural language generation | Semantic retrieval for precise matching of questions and evidence |
Industry Standard Answer: Large models are responsible for "speaking like a human"; RAG is responsible for "speaking the truth and the latest information". Practical business implementation = Large model + RAG + Vector database + Chunking strategy + Prompt engineering.
Here are clear answers to the 8 most confusing and commonly misunderstood questions.
No.
BPE: Mainstream for GPT, LLaMA series
WordPiece: Exclusive to BERT series
Unigram: Used for T5, etc.
All share the same objective: Achieve the optimal balance between vocabulary size, tokenization granularity and semantic integrity.
Because:
Randomness only exists at the initialization stage
The training objective (predicting the next word) is fixed
Consistent training data, model structure and learning rate
Vectors will converge to a similar semantic space
Random starting points do not affect the final semantic patterns.
There is a tiny accuracy loss, but it is completely acceptable.
Brute-force retrieval: 100% accurate but too slow for production
ANN: Real-time speed with almost no accuracy drop
Engineering is always about trade-offs.
No, there is a diminishing marginal return.
768/1024 dimensions meet the needs of most business scenarios
Increasing to 2048/4096 dimensions brings minimal accuracy improvement but doubles video memory/computing costs
Practical selection priority: 768 (balance) and 1024 (high accuracy).
Completely different.
Embedding models: Specialized small models with a single function—outputting vectors
Large models: General generative models for understanding, reasoning, generation and conversation
Large models have an internal Embedding layer, but it is not suitable for direct retrieval. RAG must use specialized semantic vector models.
No.
Regular databases (MySQL/ES): Only support keyword matching, no semantic understanding
Vector retrieval: Based on semantic similarity (e.g., searching for "apple" can retrieve "fruit, banana, Red Fuji")—a capability unattainable by traditional databases.
To prevent model collapse. A large single update would destroy the already learned semantic relationships. Small incremental updates (low learning rate) plus hundreds of millions of iterations enable the model to learn stable and generalizable language patterns.
It depends on the scenario:
Common sense questions (e.g., The Earth is round): Yes
Latest data, private documents and niche professional knowledge: Almost certain to hallucinate
RAG is not an added bonus, but a necessary reliability guarantee for enterprise-level AI applications.
You may forget the details, but remember this core thread:
Text → Tokenization → Random Embeddings → Iterative training adjustments → Formation of semantic vector space → Large model generates language via probabilistic prediction → RAG attaches an external knowledge base through vector retrieval → Final realization: Semantic understanding, no hallucinations, updatable, deployable.
AI is not mysterious at all. All complex designs solve four core problems:
How to digitize language?
How to make numbers represent semantics?
How to make generation more authentic?
How to make the system fast and stable?
Tokens, Embeddings, vectors and RAG are the standard answers to these four questions.
This article intentionally avoids formulas and obscure derivations, retaining only the underlying logic that programmers can immediately understand and apply to architecture design.
Mastering this framework allows you to:
Grasp the core of any large model architecture paper
Design, optimize and troubleshoot RAG systems
Distinguish between problems solvable by large models and those requiring retrieval
Avoid being misled by "AI mysticism" and "AGI myths"
The essence of AI is always: Language digitization + Semantic representation + Probabilistic generation + Engineering architecture.

May 03, 2025

May 03, 2025


Please enter your email address below and click the subscribe button. By doing so, you agree to our Terms and Conditions.
