喜讯!TCMS 官网正式上线!一站式提供企业级定制研发、App 小程序开发、AI 与区块链等全栈软件服务,助力多行业数智转型,欢迎致电:13888011868 QQ 932256355 洽谈合作!
本文提供一套完整的企业级 Ollama 服务 Kubernetes 部署方案,从命名空间隔离、持久化存储配置、Deployment 部署到 Service 暴露,详解每一步核心参数与生产级优化技巧。包含部署前环境检查、全流程操作步骤、服务验证方法及 GPU 加速、多副本扩展等实战建议,帮助开发者和运维人员快速在 K8s 集群落地稳定、可扩展的 Ollama 服务。
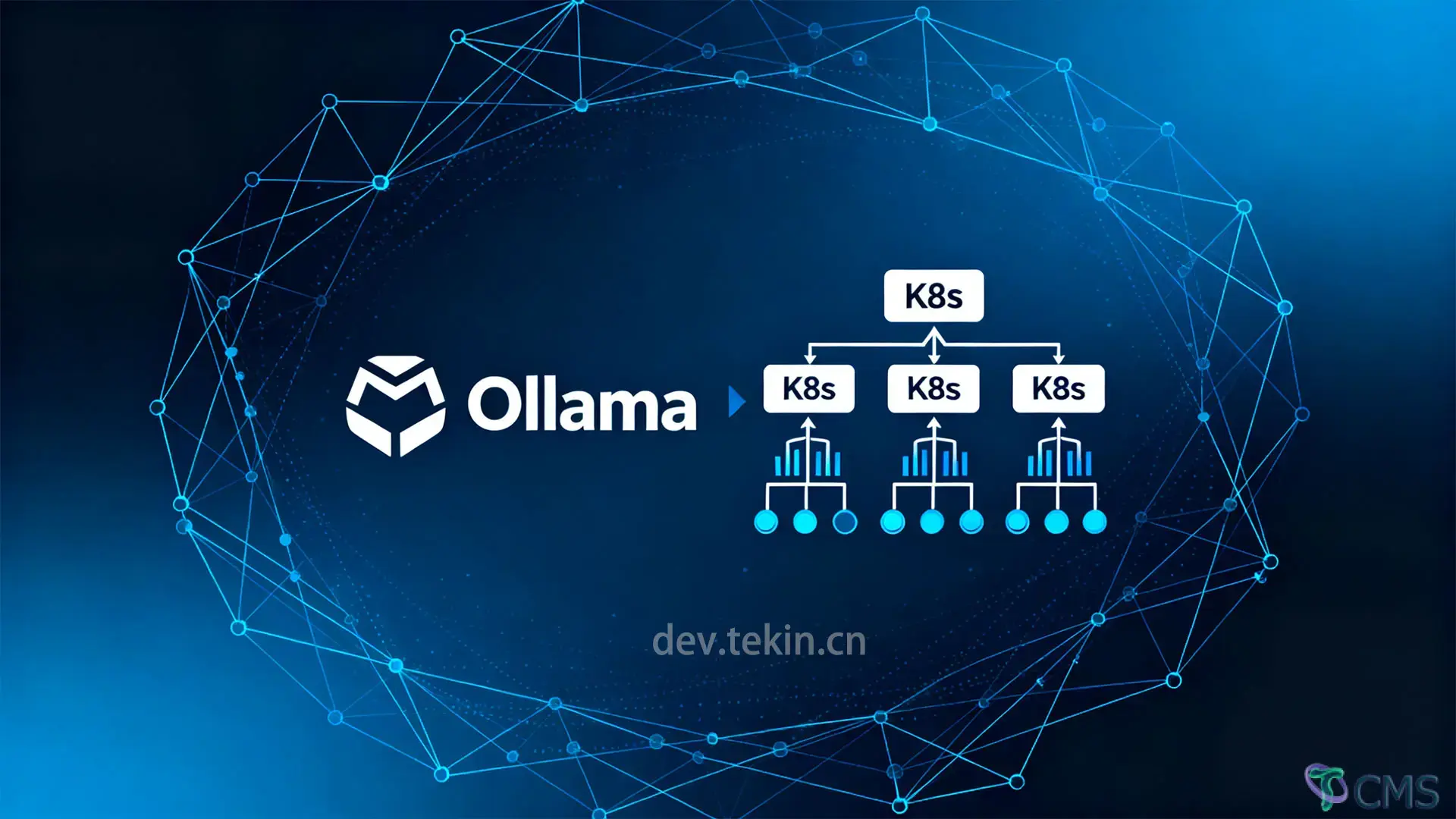
在开始部署前,需确保你的环境满足以下基础条件,避免后续配置踩坑:
K8s集群就绪:已搭建至少1节点的K8s集群(推荐1.24+版本,支持Containerd runtime),可通过kubectl get nodes验证集群状态(节点需处于Ready状态)。
存储支持:集群需具备持久化存储能力(如默认存储类、NFS、Local Path等),用于保存Ollama模型文件(模型不持久化会导致Pod重启后需重新下载)。
资源预留:根据目标模型调整节点资源——运行7B模型需至少4核CPU+8GB内存,13B模型需8核CPU+16GB内存;若用GPU加速,需提前安装NVIDIA设备插件(nvidia-device-plugin)。
工具就绪:本地安装kubectl并配置集群访问权限,可通过kubectl cluster-info验证连接有效性。
Ollama的K8s部署需包含“命名空间隔离、持久化存储、Deployment部署、Service暴露”4个核心组件。以下是完整配置文件及关键参数解读,所有配置已添加生产级注释,可直接修改后使用。
首先创建独立命名空间ollama-system,将Ollama相关资源与其他服务隔离,便于后续管理和权限控制:
# 命名空间配置:隔离Ollama资源
apiVersionv1
kindNamespace
metadata
nameollama-system # 命名空间名称,后续所有资源均在此命名空间下
labels
appollama # 统一标签,便于筛选资源Ollama默认将模型存储在/root/.ollama目录,若不做持久化,Pod重启后模型会被清空。通过PersistentVolumeClaim(PVC)申请存储,确保模型文件长期保留:
# 持久化存储配置:保存Ollama模型
apiVersionv1
kindPersistentVolumeClaim
metadata
nameollama-models-pvc # PVC名称,后续Deployment将挂载此PVC
namespaceollama-system
spec
accessModes
ReadWriteOnce # 单节点读写模式(多副本需改为ReadWriteMany,依赖存储类支持)
resources
requests
storage50Gi # 存储容量:7B模型约4GB、13B约13GB、多模型需累加(建议预留20%冗余)
# 若集群无默认存储类,需指定存储类(如local-path、nfs-client)
# storageClassName: "your-storage-class-name"关键说明:若计划部署多副本Ollama(高可用场景),需使用支持ReadWriteMany的存储(如NFS、GlusterFS),否则多Pod会因存储权限冲突导致模型加载失败。
Deployment负责管理Ollama容器的生命周期,包括资源限制、健康检查、环境变量配置等,是整个部署的核心:
# Ollama服务部署配置:管理容器运行
apiVersionapps/v1
kindDeployment
metadata
nameollama-deployment # Deployment名称
namespaceollama-system
labels
appollama
spec
replicas1 # 副本数:默认1(多副本需先解决存储共享问题,谨慎开启)
selector
matchLabels
appollama # 匹配Pod标签,用于管理Pod
template
metadata
labels
appollama # Pod标签,需与selector.matchLabels一致
spec
containers
nameollama # 容器名称
# 镜像选择:默认用latest(生产环境建议指定版本,如ollama/ollama:0.1.48)
# 若用GPU加速,替换为ollama/ollama:nvidia(需提前安装NVIDIA设备插件)
imageollama/ollamalatest
ports
containerPort11434 # Ollama默认API端口,需与Service映射
env
nameOLLAMA_HOST # 允许外部访问(默认仅localhost,必须设为0.0.0.0)
value"0.0.0.0"
nameOLLAMA_MAX_LOADED_MODELS # 最大加载模型数(默认3,根据内存调整)
value"2"
# 资源限制:根据模型大小调整,避免资源不足或浪费
resources
requests# 最小资源需求(K8s调度时参考)
cpu"2" # 7B模型建议2核,13B建议4核
memory"8Gi" # 7B模型建议8GB,13B建议16GB
limits# 最大资源限制(超出会被K8s限制)
cpu"4" # 避免CPU占用过高影响其他服务
memory"16Gi" # 防止OOM(内存溢出)
# GPU资源配置(可选,需用nvidia镜像)
# resources:
# limits:
# nvidia.com/gpu: 1 # 申请1张GPU(根据实际需求调整)
# 挂载持久化存储:将PVC挂载到Ollama模型目录
volumeMounts
namemodels-storage # 卷名称,需与下方volumes.name一致
mountPath/root/.ollama # Ollama模型默认存储路径,不可修改
# 健康检查:确保服务正常运行,避免无效Pod对外提供服务
livenessProbe# 存活检查:失败会重启Pod
tcpSocket
port11434
initialDelaySeconds30 # 启动后延迟30秒检查(首次加载模型较慢)
periodSeconds10 # 每10秒检查一次
readinessProbe# 就绪检查:失败会从Service移除Pod
tcpSocket
port11434
initialDelaySeconds10 # 启动后10秒开始检查
periodSeconds5 # 每5秒检查一次
# 定义卷:关联PVC与容器挂载点
volumes
namemodels-storage
persistentVolumeClaim
claimNameollama-models-pvc # 关联前面创建的PVC名称核心参数解读:
OLLAMA_HOST: 0.0.0.0:必须配置,否则Ollama仅监听容器内部localhost,外部无法访问;
资源限制:若运行13B及以上模型,需将cpu调整为4核+、memory调整为16GB+,否则模型加载会超时;
GPU配置:需同时满足“使用nvidia镜像+配置GPU资源限制+集群安装NVIDIA设备插件”三个条件,缺一不可。
Deployment创建的PodIP是临时的,需通过Service固定访问地址,实现“Pod动态变化但访问地址不变”:
# 服务暴露配置:固定Ollama访问地址
apiVersionv1
kindService
metadata
nameollama-service # Service名称,集群内访问用此名称
namespaceollama-system
spec
selector
appollama # 匹配Ollama的Pod标签,将流量转发到对应Pod
ports
port11434 # Service暴露的端口(集群内访问用此端口)
targetPort11434 # 对应Pod的端口(需与Deployment的containerPort一致)
typeClusterIP # 访问类型:默认集群内访问(外部访问需修改为NodePort/LoadBalancer)访问类型说明:
ClusterIP:仅K8s集群内可访问,地址为ollama-service.ollama-system:11434(适合集群内其他服务调用);
NodePort:通过节点IP+固定端口访问(如node-ip:30080),需添加nodePort: 30080(端口范围30000-32767);
LoadBalancer:云厂商环境使用(如AWS ELB、阿里云SLB),自动分配公网IP,无需手动配置端口。
将上述4个组件的配置整合为一个YAML文件(如ollama-k8s-deploy.yaml),执行部署命令:
# 部署Ollama相关资源
kubectl apply -f ollama-k8s-deploy.yaml执行后,通过以下命令查看资源状态,确保所有组件正常:
# 查看命名空间是否创建成功
kubectl get ns | grep ollama-system
# 查看PVC是否绑定成功(STATUS需为Bound)
kubectl get pvc -n ollama-system
# 查看Deployment状态(READY需为1/1)
kubectl get deployment -n ollama-system
# 查看Pod状态(STATUS需为Running,RESTARTS为0)
kubectl get pods -n ollama-system若Pod状态为Pending,可能是“存储未绑定”或“资源不足”,可通过kubectl describe pod <pod-name> -n ollama-system查看具体原因。
Pod运行正常后,需进入容器拉取所需模型(如Llama3-8B、Qwen-7B):
# 进入Ollama容器(替换<pod-name>为实际Pod名称)
kubectl exec -it -n ollama-system <pod-name> -- /bin/sh
# 在容器内拉取模型(以Llama3-8B为例)
ollama pull llama3:8b拉取过程依赖网络速度(7B模型约4GB),可通过kubectl logs -f <pod-name> -n ollama-system查看拉取进度。
在K8s集群内其他Pod(如测试用的busybox)中,通过Service地址测试API:
# 进入测试Pod
kubectl run -it busybox --image=busybox:1.35 -- /bin/sh
# 测试模型列表接口(返回已拉取的模型)
wget -qO- http://ollama-service.ollama-system:11434/api/tags通过kubectl port-forward将Service端口转发到本地,实现本地访问:
# 将集群内ollama-service的11434端口转发到本地11434端口
kubectl port-forward -n ollama-system service/ollama-service 11434:11434转发成功后,本地浏览器访问http://localhost:11434,或通过curl测试对话接口:
# 调用Ollama对话API(提问“什么是Kubernetes?”)
curl http://localhost:11434/api/chat -d '{
"model": "llama3:8b",
"messages": [{"role": "user", "content": "什么是Kubernetes?"}]
}'若返回JSON格式的对话结果,说明Ollama服务已正常工作。
多副本场景:使用NFS或云存储(如AWS EFS、阿里云NAS),确保accessModes: ReadWriteMany;
性能优化:模型加载依赖磁盘IO,生产环境建议使用SSD(机械硬盘加载13B模型可能超时)。
根据模型动态调整:13B模型建议cpu: 4-8核、memory: 16-32GB,34B模型需cpu: 8核+、memory: 64GB+;
GPU加速:若有NVIDIA GPU,优先使用ollama/ollama:nvidia镜像,模型加载速度可提升3-5倍,对话响应延迟降低50%以上。
监控配置:Ollama暴露/metrics端点,可通过Prometheus+Grafana监控“模型加载状态、API请求量、响应延迟”;
日志收集:将容器日志输出到ELK或 Loki,便于排查模型加载失败、API报错等问题;
自动重启:添加PodDisruptionBudget(PDB),避免运维操作导致服务中断。
权限控制:为命名空间添加RBAC权限,仅允许指定用户操作Ollama资源;
网络隔离:使用NetworkPolicy限制访问来源,仅允许信任的服务访问11434端口;
镜像安全:使用私有镜像仓库存储Ollama镜像,避免官方镜像被篡改。
本文提供的Ollama服务K8s部署方案,覆盖了“持久化存储、资源管控、服务暴露、测试验证”全流程,既适合测试环境快速上手,也可通过“存储优化、GPU加速、监控配置”适配生产需求。核心优势在于:
模型持久化:通过PVC避免Pod重启后模型丢失,减少重复下载;
资源可控:通过requests/limits限制资源占用,避免影响其他服务;
灵活扩展:支持单副本调试、多副本高可用、GPU加速等多种场景。
实际部署时,可根据“模型大小、集群环境、访问需求”调整配置(如存储容量、资源限制、Service类型),即可快速落地轻量级AI服务。
以下是完整的Ollama服务K8s部署配置(包含模型持久化、资源优化和健康检查):
# ollama-deployment.yaml
apiVersionapps/v1
kindDeployment
metadata
nameollama
namespaceai-services # 建议独立命名空间管理AI服务
labels
appollama
spec
replicas1 # 模型服务通常单副本,如需扩展需考虑模型同步
selector
matchLabels
appollama
strategy
typeRecreate # 重建策略,避免多副本模型文件冲突
template
metadata
labels
appollama
spec
containers
nameollama
imageollama/ollamalatest
imagePullPolicyAlways
ports
containerPort11434
nameapi
protocolTCP
# 模型存储目录挂载(关键:避免重启后重新拉取模型)
volumeMounts
namemodel-storage
mountPath/root/.ollama
subPathollama # 共享存储时隔离目录
namecache-volume
mountPath/root/.cache/ollama
# 启动命令:先拉取模型再启动服务(支持多模型)
command"/bin/sh" "-c"
args
set -e
# 预拉取需要的模型(根据业务需求调整)
ollama pull llama3:8b-instruct
ollama pull qwen:7b-chat # 可选:添加阿里通义千问模型
# 启动服务并绑定到0.0.0.0(允许容器外部访问)
ollama serve --host 0.0.0.0
# 资源限制(根据模型大小调整,8B模型建议最低配置)
resources
requests
cpu"4" # 至少4核CPU(推理加速)
memory"12Gi" # 8B模型建议12GB+内存
limits
cpu"8"
memory"16Gi"
# 健康检查
livenessProbe
httpGet
path/
port11434
initialDelaySeconds120 # 模型加载需要时间,延迟检查
periodSeconds20
timeoutSeconds5
readinessProbe
httpGet
path/
port11434
initialDelaySeconds60
periodSeconds10
# 安全上下文:允许写入模型目录
securityContext
runAsUser1000
runAsGroup1000
fsGroup1000
# 节点亲和性:优先调度到GPU节点(如有)
affinity
nodeAffinity
preferredDuringSchedulingIgnoredDuringExecution
weight100
preference
matchExpressions
keynvidia.com/gpu.present
operatorIn
values
"true"
# 污点容忍:允许调度到有GPU污点的节点
tolerations
key"nvidia.com/gpu"
operator"Exists"
effect"NoSchedule"
# 模型存储持久卷声明(生产环境必配)
volumes
namemodel-storage
persistentVolumeClaim
claimNameollama-models-pvc # 需提前创建对应的PVC
namecache-volume
emptyDir# 临时缓存目录,加速模型加载
mediumMemory
sizeLimit2Gi
---
# Ollama服务访问入口
apiVersionv1
kindService
metadata
nameollama-service
namespaceai-services
labels
appollama
spec
selector
appollama
ports
port11434
targetPortapi
protocolTCP
namehttp
typeClusterIP # 集群内部访问,如需外部访问可改为NodePort/LoadBalancer
---
# 模型存储持久卷声明(PVC)
apiVersionv1
kindPersistentVolumeClaim
metadata
nameollama-models-pvc
namespaceai-services
spec
accessModes
ReadWriteOnce # 单节点读写(多副本需ReadWriteMany,如NFS)
resources
requests
storage50Gi # 8B模型约占10GB,预留扩展空间
storageClassName"standard" # 根据集群存储类调整(如aws-ebs、nfs-client等)模型持久化:通过PVC挂载/root/.ollama目录,避免容器重启后重复拉取模型(8B模型约10GB,节省带宽和时间)。
资源配置:根据模型参数调整(8B模型建议12GB+内存,13B模型需24GB+),CPU核数影响推理速度。
多模型支持:在args中通过ollama pull命令预加载多个模型(如llama3、qwen等)。
GPU支持:通过节点亲和性和污点容忍,优先调度到GPU节点(需集群已配置NVIDIA设备插件),GPU可显著加速推理。
健康检查:延长初始检查延迟,适配模型加载的耗时特性。
先创建PVC所需的PersistentVolume(或依赖集群默认存储类)
部署配置:kubectl apply -f ollama-deployment.yaml
验证:kubectl logs -f deployment/ollama -n ai-services 查看模型拉取和服务启动日志

12月 01, 2025

11月 25, 2025

11月 26, 2025

11月 16, 2025

11月 12, 2025

11月 14, 2025
11月 04, 2025

11月 04, 2025

11月 04, 2025

10月 31, 2025

在下方输入邮箱地址后,点击订阅按钮即可完成订阅,同时代表您同意我们的条款与条件。