喜讯!TCMS 官网正式上线!一站式提供企业级定制研发、App 小程序开发、AI 与区块链等全栈软件服务,助力多行业数智转型,欢迎致电:13888011868 QQ 932256355 洽谈合作!
本文完整呈现2019-2026年大语言模型从技术萌芽到产业成熟的全过程,梳理关键节点、技术派系、架构演进与生态格局变化,深度解读从预训练、对齐革命到MoE普及、国产模型主导开源的完整脉络,为AI从业者提供系统化行业参考。
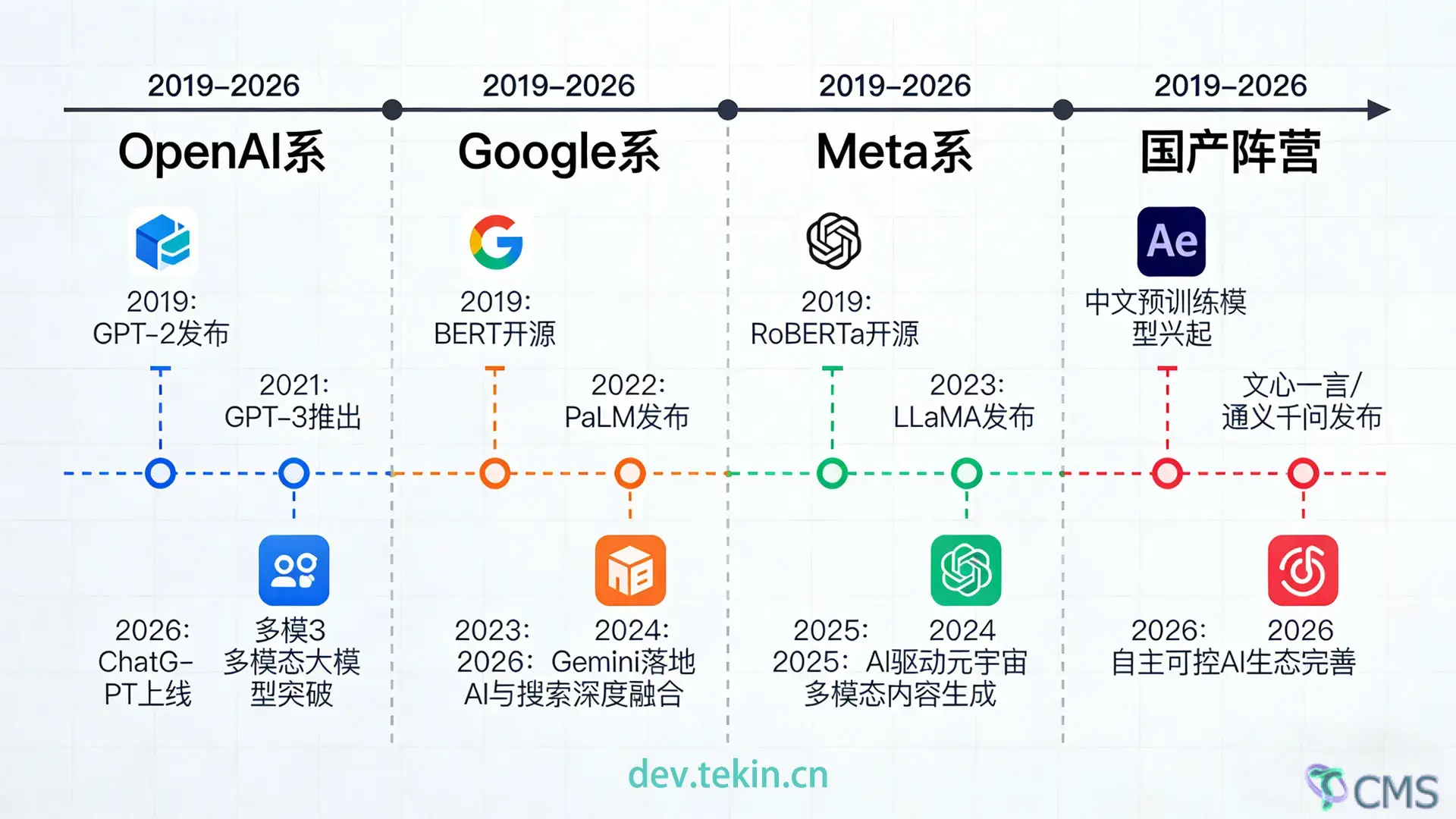
本文以时间为轴线,系统梳理2019-2026年大语言模型(LLM)的发展历程,重点拆解2019-2023年的奠基爆发期与2023-2026年的生态成熟期核心脉络。结合经典技术图谱与最新行业数据,剖析四大技术派系的迭代逻辑,解读MoE架构普及、中国力量崛起、场景化细分等关键产业趋势,为技术从业者构建兼具历史深度与前瞻价值的大模型认知体系。
2019年,GPT-3的发布标志着人工智能正式进入“大模型时代”;2022年,ChatGPT的出圈让LLM从实验室走向全民;2026年,开源生态百花齐放,国产模型主导全球格局。短短7年,大模型完成了从“技术探索”到“产业基础设施”的跨越,重构了AI研发范式与商业版图。
本文将通过“奠基期-爆发期-成熟期”三阶段划分,完整还原2019-2026年大模型的演进之路,厘清技术脉络、派系格局与产业变迁的底层逻辑。
这一阶段是大模型的“从0到1”,核心完成了技术范式确立、对齐革命爆发与开源门槛降低三大核心任务,为后续生态成熟奠定基础。
2019年是大模型的“萌芽之年”,两款里程碑式产品奠定了整个行业的技术根基:
OpenAI GPT-3:1750亿参数规模刷新纪录,首次证明“大参数+海量数据”的预训练模式可实现通用语言能力,成为后续所有生成式大模型的基座雏形。
Google T5:提出“统一文本到文本”框架,将所有自然语言处理任务转化为生成任务,为跨任务适配提供了全新思路。
此时的大模型仍处于“实验室阶段”,部署成本极高、落地场景有限,但“预训练+微调”的核心范式已确立,开启了大模型的研发竞赛。
这两年是大模型的“蓄力期”,欧美巨头持续深耕技术,国内玩家完成初步布局,形成“欧美领跑、国内跟跑”的格局:
欧美巨头技术迭代:Google推出GShard(模型并行技术突破)、mT5(多语言预训练优化);OpenAI发布Codex,实现代码生成的重大突破,为后续GitHub Copilot奠定基础。
国产模型初步亮相:华为PanGu-α、百度Ernie 3.0相继发布,聚焦中文场景与自主可控,在知识增强、多模态融合等方向进行差异化探索。
技术特征:参数规模持续攀升,模型并行、稀疏化等技术开始应用,大模型从“通用能力”向“细分领域”初步延伸。
2022年是大模型的“颠覆之年”,核心转折点是ChatGPT的发布,彻底解决了大模型与人类意图的“对齐问题”:
上半年:基座模型混战:Google PaLM、Meta OPT、阿里通义千问初代等数十款基座模型密集发布,参数规模突破万亿,预训练技术日趋成熟。
下半年:RLHF开启新时代:OpenAI通过人类反馈强化学习(RLHF),让ChatGPT具备了精准理解人类指令、流畅对话的能力,引爆消费级市场,推动大模型从“能做事”向“会做事”转变。
国产跟进:百度文心一言、科大讯飞星火认知大模型等相继立项,国内大模型竞赛正式进入“对齐赛道”。
2023年是大模型的“开源元年”,Meta的关键决策打破了巨头垄断,推动生态走向平民化:
核心转折点:Meta开源LLaMA系列模型,凭借高效的基座性能与开放的授权策略,成为全球开发者的首选微调基座。
开源生态爆发:基于LLaMA的微调模型(Vicuna、Alpaca)批量涌现,国产开源模型(百川、书生浦语、千问1.0开源版)快速崛起,“公开可用(Publicly Available)”成为行业核心趋势。
技术突破:GPT-4发布,实现多模态能力的重大跨越;国产模型在中文理解、低成本部署上形成优势,初步实现“从跟跑到并跑”的转变。
截至2023年底,大模型完成了从“闭源垄断”到“开源共治”的格局转变,技术门槛大幅降低,为2023年后的生态爆发埋下伏笔。
2023年下半年至2026年,大模型进入“从1到N”的成熟期,核心逻辑从“堆参数、拼规模”转向“提效率、做细分、重落地”,中国力量崛起、MoE架构普及、场景化落地成为三大核心特征。
这一阶段的核心是技术路线的重构,行业彻底告别“参数内卷”,转向“高效激活”的技术方向:
MoE架构崛起:面对大参数模型的高推理成本,混合专家(MoE) 架构成为主流——通过“总参数大、激活参数小”的设计,兼顾性能与成本。Google Gemini 1.0、智谱GLM-4、Meta Llama 3等率先采用MoE架构,验证了其工业化落地的可行性。
国产模型弯道超车:千问2.0、DeepSeek-V3等国产模型通过MoE架构优化,在中文推理、代码生成上实现对欧美模型的局部超越;开源生态中,国产模型下载量占比持续提升。
场景化初步落地:大模型开始从“通用对话”转向“行业适配”,金融、政务、医疗等领域的定制化模型批量出现,API调用成为主流商用模式。
2025年是大模型的“生态分化年”,全球格局呈现“中国主导开源、欧美坚守闭源高端”的特征:
国产开源生态领跑:阿里、智谱、深度求索、零一万物等企业持续迭代开源模型,在中文场景、工程化部署、成本控制上形成绝对优势;Hugging Face中文开源模型下载量占比突破60%。
欧美阵营差异化竞争:Meta深耕Llama生态,通过版本迭代巩固开发者基础;Mistral AI聚焦欧洲合规市场,推出GDPR认证模型;OpenAI、Google则坚守闭源高端市场,主打GPT-5、Gemini 2.0的旗舰性能。
端侧大模型爆发:随着芯片技术的进步,轻量级开源模型(如7B、13B参数)实现端侧部署,手机、汽车、物联网设备成为大模型新的落地载体。
2026年,大模型生态已完全成熟,成为与云计算、大数据并列的产业基础设施,核心特征如下:
格局固化:开源市场形成“中国8席、欧美2席”的TOP10格局(千问3.5、GLM-5领跑),闭源市场由GPT-5.2、Gemini 3主导,两者边界模糊,形成“开源基座+闭源增值”的商业模式。
技术成熟:MoE架构成为绝对主流,激活参数与推理效率达到最佳平衡;多模态融合、智能体技术、长文本处理成为核心竞争点。
落地普惠:大模型渗透到各行各业,开发者可通过“开源模型本地部署”或“免费API调用”快速实现AI赋能,研发门槛降至历史最低。
纵观7年发展,全球大模型形成了四大核心派系,各有明确的技术路线与产业定位,共同推动生态成熟:
| 派系 | 核心代表产品 | 技术路线演进 | 产业定位 |
|---|---|---|---|
| OpenAI系 | GPT-3 → ChatGPT → GPT-4 → GPT-5.2 | 预训练→RLHF对齐→多模态→智能体 | 闭源高端市场标杆,商业化落地最成熟 |
| Google系 | T5 → PaLM → PaLM2 → Gemini 3 | 大参数预训练→多模态融合→MoE架构 | 技术研发领跑者,聚焦高端科研与企业服务 |
| Meta系 | OPT → LLaMA → LLaMA2 → LLaMA4 | 闭源基座→开源普惠→MoE生态→端侧适配 | 开源生态根基,构建全球开发者护城河 |
| 国产阵营 | PanGu-α → Ernie 3.0 → 千问3.5/GLM-5 | 知识增强→中文对齐→MoE优化→场景化细分 | 开源市场主导者,聚焦本土落地与自主可控 |
2019-2022:核心是参数内卷,通过提升参数规模、数据量实现能力突破;
2023-2026:核心是效率优化,从MoE架构、稀疏化推理、端侧适配等方向,解决“性能与成本”的核心矛盾。
2019-2022:少数科技巨头掌握核心技术,大模型是“稀缺资源”;
2023-2026:开源浪潮打破垄断,开发者、中小企业成为生态核心,大模型成为“公共基础设施”。
早期:追求“全知全能”的通用对话能力,面向C端消费者;
成熟期:聚焦“行业适配”的细分能力,面向B端企业,场景化成为模型突围的关键。
2019-2026年,大语言模型的发展是一部“技术迭代与产业变革”的双重史诗。从GPT-3的范式确立,到ChatGPT的对齐革命,再到2026年的生态成熟,大模型完成了从“实验室技术”到“产业基础设施”的完整闭环。
如今,中国力量在开源市场的主导地位,MoE架构的全面普及,场景化落地的深度渗透,标志着大模型已进入“普惠时代”。对于技术从业者而言,无需再盲目追逐“最大的模型”,而是要基于场景需求,选择“最合适的模型”——这正是7年演进留给行业的核心启示。
未来,随着端侧大模型、智能体协同、多模态融合的持续突破,大模型将进一步渗透到生产生活的每一个角落,推动人工智能进入全新的发展阶段。
本人长期专注于大模型底层原理、RAG 企业级落地、AI 应用架构设计,可提供: 企业 AI 落地方案咨询 RAG 系统优化与排错 大模型应用开发技术支持 AI 企业应用开发技术咨询 微信/QQ:93225635 微信公众号:技术与认知
2月 25, 2026
12月 29, 2025
2月 25, 2026
2月 04, 2026
2月 04, 2026
12月 29, 2025

12月 21, 2025
12月 19, 2025

12月 17, 2025
12月 01, 2025

在下方输入邮箱地址后,点击订阅按钮即可完成订阅,同时代表您同意我们的条款与条件。