喜讯!TCMS 官网正式上线!一站式提供企业级定制研发、App 小程序开发、AI 与区块链等全栈软件服务,助力多行业数智转型,欢迎致电:13888011868 QQ 932256355 洽谈合作!
本文深度解析 AI 大模型底层核心逻辑,从 Token 分词、Embedding 语义向量,到 RAG 检索增强生成全链路讲解,用直白语言拆解大模型 “理解语言” 的原理,帮助 AI 入门与企业开发者吃透 Token、向量、检索、生成等关键技术,夯实 AI 应用开发基础。
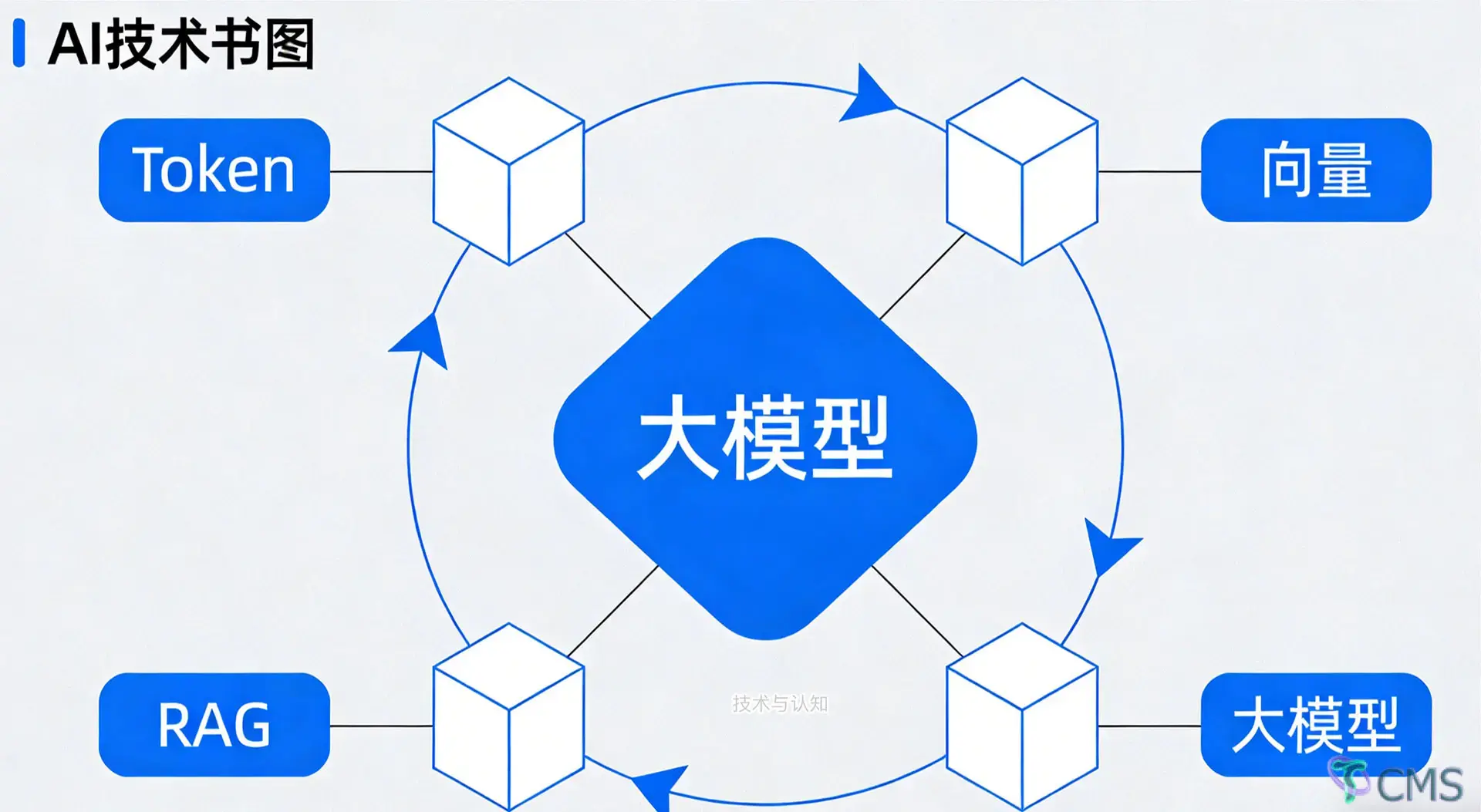
在大模型与 RAG 技术全面落地的今天,绝大多数开发者仍停留在调用 API、改 Prompt 的层面: 知道大模型能对话、RAG 能减少幻觉,却不清楚语言是怎么被模型理解的、向量为什么能代表语义、检索和生成为什么要这么配合。
本文不讲花哨框架,不堆复杂公式,只从最底层逻辑出发: 从 Token 分词、Embedding 向量,到语义表示、检索增强生成 RAG,把大模型“听懂—思考—回答”的全链路讲透。 适合:AI 入门、后端转 AI、想真正吃透原理而不只会用工具的开发者。
人类的文字,对模型来说只是一串无意义符号。 大模型要处理语言,第一步必须把自然语言 → 模型可识别的最小单元,这个单元就是:Token(词元)。
Token 不是字,不是词,而是模型定义的最小处理单位。
英文:常拆成词根、前缀、单词
中文:常拆成单字、常用词
例如:
RAG的主要作用是什么?
会被拆成:
RAG / 的 / 主要 / 作用 / 是 / 什么
每一个片段,都会被映射成一个唯一的数字 ID,相当于给语言一个“身份证号”。 模型不看文字,只看这些数字序列。
如果把所有词都塞进词表:
词表会爆炸(几十万、几百万)
显存占用巨大、计算低效
所以现代模型统一使用BPE(Byte Pair Encoding)子词分词算法:
高频词保留完整
低频词拆成更小单元
生僻词、新词继续拆,直到命中词表
核心目的: 用有限大小的词表(通常 3万~30万),覆盖几乎所有语言场景, 同时保证语义不丢失、计算可负担。
一句话总结: Token = 语言数字化的入口;BPE = 控制词表规模的最优解。
Token 只是把文字变成了数字编号,没有语义。 真正让 AI 理解“意思”的关键一步,是 Embedding(词向量/句向量)。
Embedding 的本质: 把一段文本,映射到一个高维空间里的一个点(向量)。
语义相近的文本,在空间里距离更近; 语义无关的文本,距离更远。
这就是所有语义搜索、推荐、RAG的底层数学基础。
很多初学者误区: 以为 Embedding 是提前写好的“含义字典”。 完全不是。
模型初始化时,会建一张超大表:词表大小 × 向量维度
表里全是 -1 ~ +1 的随机小数
每个 Token ID 对应表中一行,就是初始向量
这时的向量没有任何语义,只是一串随机数字。
向量维度,可以理解为描述语义的特征数量。
768 维 = 用 768 个“隐藏特征”描述一个词/一句话
特征由模型自动学习,不需要人工标注(如词性、情感、主题等)
为什么多是 2 的倍数? 不是数学玄学,是工程硬件决定:
GPU/NPU 底层是并行计算
内存读取要求地址对齐
2 的幂次维度(128、256、1024)能最大化利用带宽、减少内存碎片
768 虽不是 2 的幂,但 768 = 3 × 256,
256 是主流芯片标准块大小,因此也能高效计算,成为 BERT、LLaMA 等模型标配。
初始向量是乱的,语义是靠预测任务逼出来的。
典型流程(以自回归模型为例):
输入文本 → 查表得到 Token 向量
模型做任务:预测下一个词
把预测结果和真实答案对比,计算 Loss
反向传播,极小幅调整所有向量
重复上亿次迭代
最终形成稳定规律:
相似上下文的词(苹果、香蕉、橙子)→ 向量靠近
无关词(苹果、键盘、宇宙)→ 向量远离
一句话击穿本质: Embedding 不是设计出来的,是“逼”出来的。 向量距离 = 语义相似度。
大模型有两个天生缺陷:
知识截止:训练完就不再更新
幻觉:没见过的内容也敢一本正经胡说
RAG(Retrieval-Augmented Generation)检索增强生成,就是为解决这两个问题而生的工程架构,而非新模型。
标准 RAG 分为两大阶段:
文档切分(Chunking) 长文档切成小段,保证:
语义完整
不超 Embedding 模型长度限制
不超大模型上下文窗口
向量化(Embedding) 每一段文本 → 向量
存入向量数据库 并建立索引(如 HNSW),用于快速近似最近邻搜索(ANN)
用户问题 → 向量化
向量检索:在库中找出最相似的若干片段
提示词拼接:问题 + 参考片段 → 送入大模型
生成回答:模型只基于给定材料作答
RAG 的本质: 把大模型从“闭卷考试”,变成开卷考试。
很多新手问:整篇文档直接向量化不行吗? 不行,原因非常工程化:
Embedding 模型有最大输入长度,超长会被截断或报错
太长语义会被“平均化”,检索精度暴跌
上下文窗口有限,大模型读不下整本书
检索召回不精准,无法定位到真正包含答案的那几句话
文本切分,是 RAG 效果好坏的关键工程步骤。
向量检索如果暴力比对(全库算距离),数据一大就卡死。 工业界一律用 ANN(Approximate Nearest Neighbor)近似最近邻。
核心思想: 牺牲一点点精度,换数量级的速度提升。
通过树、图等索引结构(如 HNSW):
不用全量比对
只在候选集中精筛
精度通常能保持 95%+
速度提升几十、上百倍
这是 RAG 能在线实时响应的底层支撑。
这是面试、架构设计中最常被混淆的点。
| 对比维度 | 大模型 | RAG |
|---|---|---|
| 本质 | 生成式模型,负责理解与生成语言 | 检索+生成的技术架构,不是模型 |
| 角色 | 大脑 | 外部工具书 + 检索器 |
| 知识来源 | 训练数据,固定、不可实时更新 | 外部知识库,随时增删改查 |
| 最大问题 | 幻觉、过时、无法访问私有数据 | 解决幻觉,保证回答基于真实资料 |
| 核心能力 | 概率接龙,生成流畅自然语言 | 语义检索,精准匹配问题与证据 |
工业界标准答案: 大模型负责“说人话”,RAG 负责“说真话、说新话”。 实际业务 = 大模型 + RAG + 向量库 + 分块策略 + 提示工程。
我把最容易被问懵、最容易理解错的问题,一次性讲清。
不是。
BPE:GPT、LLaMA 系列主流
WordPiece:BERT 系
Unigram:T5 等
目标完全一致: 在词表大小、分词粒度、语义完整性之间做最优权衡。
因为:
随机只在初始化那一刻
训练目标(预测下一个词)是确定的
数据、结构、学习率一致
向量会收敛到相似的语义空间
随机起点,不影响最终语义规律。
会有微小损失,但完全可接受。
暴力检索:准,但慢到无法上线
ANN:快到可实时,精度几乎不跌 工程永远是trade-off(权衡)。
不是,存在边际效益递减。
768 / 1024 已经能满足绝大多数业务
升到 2048、4096:精度提升很小,显存/算力翻倍 实际选型优先:768(平衡)、1024(高精度)。
完全不是一个东西。
Embedding 模型:专用小模型,只做一件事——输出向量
大模型:通用生成模型,理解、推理、生成、对话 大模型内部也有 Embedding 层,但不适合直接拿来做检索。 RAG 必须用专用语义向量模型。
不行。
MySQL/ES 关键词匹配:只看字,不看意思
向量检索:看语义相似度 搜“苹果”,能召回“水果、香蕉、红富士”, 这是传统数据库做不到的。
因为要避免模型学崩。 一步改太大,会破坏已经学到的语义关系。 小步慢走(低学习率)+ 海量迭代, 才能让模型学到稳定、泛化的语言规律。
分场景:
常识问题(地球是圆的):可以
最新数据、私有文档、细分专业知识:基本必幻觉 RAG 不是锦上添花, 是企业级应用必须的可靠性保障。
你可以记不住细节,但一定要记住这条主线:
文字 → Token 化 → 转成随机 Embedding → 训练中不断修正 → 语义向量空间形成 → 大模型靠概率预测生成语言 → RAG 用向量检索外挂知识库 → 最终实现:懂语义、不瞎编、可更新、可落地。
AI 根本不玄学,所有复杂设计,都在解决四个问题:
怎么把语言变成数字?
怎么让数字代表语义?
怎么让生成更真实?
怎么让系统又快又稳?
Token、Embedding、向量、RAG,就是这四问的标准答案。
这篇文章,我刻意避开了公式与晦涩推导,只保留程序员能立刻看懂、能直接用于架构的底层逻辑。
真正吃透这一套:
你能看懂任何大模型架构论文的核心
你能设计、优化、排坑 RAG 系统
你能分清:什么能用大模型解决,什么必须靠检索
你不会再被“AI 玄学、 AGI 神话”带偏
AI 的本质,始终是: 语言数字化 + 语义表示 + 概率生成 + 工程架构。
希望这篇文章,能成为你从“AI 使用者”走向“AI 理解者”的第一步。
作者简介 / 技术咨询 本人长期专注于大模型底层原理、RAG 企业级落地、AI 应用架构设计,可提供: 企业 AI 落地方案咨询 RAG 系统优化与排错 大模型应用开发技术支持 AI 企业应用开发技术咨询 微信/QQ:93225635 微信公众号:技术与认知
2月 25, 2026
12月 29, 2025
2月 25, 2026
2月 04, 2026
2月 04, 2026
12月 29, 2025

12月 21, 2025
12月 19, 2025

12月 17, 2025
12月 01, 2025

在下方输入邮箱地址后,点击订阅按钮即可完成订阅,同时代表您同意我们的条款与条件。